9.4 用pyplot画散点图
散点图是探测两个变量是否具有相关性的最简单的方法,但是要画一张高质量的散点图并不容易。接下来我们用4.5节所提到的行为危险因素监控系统(BRFSS)中的身高和体重做图。pyplot中提供了一个画散点图的函数scatter:
import matplotlib.pyplot as pyplot pyplot.scatter(heights, weights)
图9-2是画出来的结果。从图中可以看到二者确实是正相关的,身高较高的人体重较大。但这个结果并不理想,图中明显可以看到数据点被分成一列列的。这是因为在收集身高数据时,是以英寸为基本单位收集的,转换成厘米之后也进行了取整。这样就丢失了一些信息。
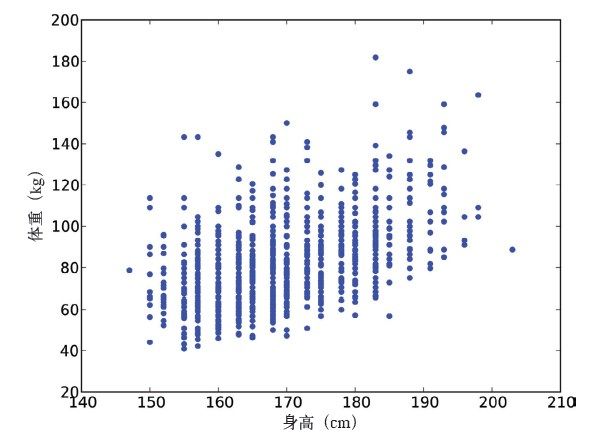
图9-2 BRFSS中被调查者体重—身高简易散点图
显然那些丢失的信息已经无可挽回,但我们可以给每个身高数据加一个随机扰动来尽可能地使数据回到之前的样子。因为数据是以英寸为单位收集的,我们可以给它们加上一个扰动(jitter),这里给它们加上一个[-0.5, 0.5]英寸上的均匀分布的随机数,换算成厘米后的范围是[-1.3, 1.3]:
jitter = 1.3
heights = [h + random.uniform(-jitter, jitter) for h in heights]
图9-3展示了处理后的数据的散点图。图中的趋势更加明显了。一般情况下我们可以通过这种方法来得到更有说服力的图,不过,在进行数据分析时就必须用原始数据。
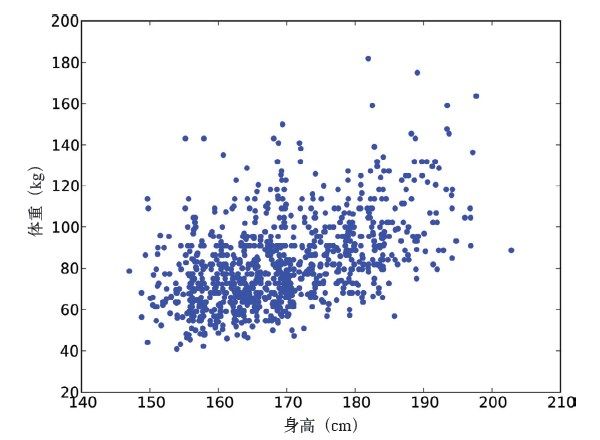
图9-3 数据进行扰动处理后的散点图
即使进行了上述数据扰动处理,我们可能依然无法很好地展示数据。因为图中有很多点重叠在一起,这样就隐藏了图中密集度高的一些数据的信息,同时可能会过分凸显那些异常值。
我们可以引入一个透明度参数α来解决这个问题:
pyplot.scatter(heights, weights, alpha=0.2)
图9-4展示了增加透明度后的结果。图中有重叠的点看起来颜色更深了,这样颜色深度就跟点的密度成比例地变化。图中在90 kg附近有一个明显的横线,数据是被调查者提供的,所以这里最可能的原因是人们对体重的数据进行了取整(或许他们想让自己的体重看起来更轻一些)。
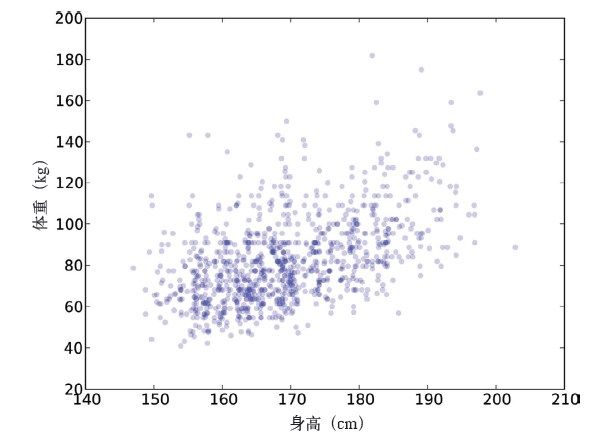
图9-4 数据进行扰动处理并引入透明度参数后的散点图
这样的图很适合用在那些数据量不是很大的情况。这里我们仅用了BRFSS中的1000个数据,而BRFSS总共包含了414 509个数据。
当我们要处理大量的数据时,上述方法可能看起来都会一团糟。我们可以用一种称为hexbin的方法来处理这样的问题:首先将图分成一个个小格子,统计每个格子中有多少个数据点,然后根据格子中点的个数来上色。pyplot提供了一个hexbin函数来实现这个功能:
pyplot.scatter(heights, weights, cmap=matplotlib.cm.Blues)
图9-5展示了hexbin的结果。这种图的好处是能展示出数据关系的整体形状,对于大型数据集非常高效,但缺点是我们可能看不见那些异常值了。
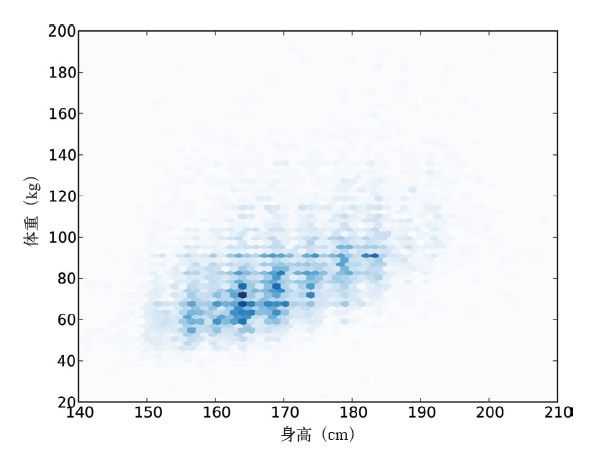
图9-5 使用hexbin函数绘制的散点图
上述例子告诉我们,要画一张能真实反映数据关系的散点图并不是一件容易的事情。读者可以从http://thinkstats.com/brfss_scatter.py下载到本节画图所用的代码。