7.1 均值差异的检验
统计检验中最简单的一种检验是比较两组数据的均值是否存在差异。在NSFG数据中,我们发现第一胎婴儿怀孕周期的均值略长于非第一胎婴儿怀孕周期的均值,同时第一胎婴儿出生体重的均值略轻于非第一胎婴儿出生体重的均值。接下来我们将检验这些差异是否具有统计显著性。
在上述两个例子中,原假设是两个分组的分布相同,出现上述差异是随机因素引起的。
为了计算p值,我们把所有婴儿(包括第一胎和非第一胎)的数据混在一起。然后重新随机分成两组:第一组的样本个数等于第一胎婴儿的样本数,第二组的样本个数等于非第一胎婴儿的样本数。每次分完组后,计算两个分组的均值的差。这个差值相当于在原假设(两个分组没有差异)下观测到的差值。
如果我们产生足够数量的这种分组样本,可以统计有多少个差值(由于随机因素引起的)大于等于实际上我们观测到的差值,这个比例就是p值。
就怀孕周期而言,我们观察了n=4413个第一胎婴儿,m=4735个非第一胎婴儿。两组样本均值的差值为δ=0.078周。为了计算这个效应的p值,将两个分组的数据合在一起,然后随机将这些数据分成两组,一组的样本数为n,另一组为m,再计算这两个分组的均值的差。
这是重抽样(resampling)的一个例子,因为我们是从一个分布的样本数据里面重新随机地抽取样本。我们随机产生了1000次这样的过程,这些差值的分布如图7-1所示。
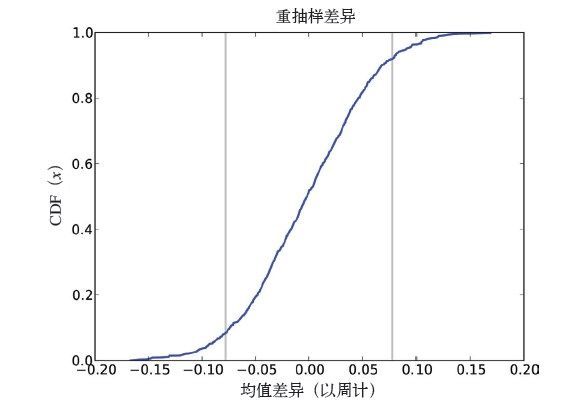
图7-1 重抽样数据均值差异的CDF
从图中我们发现差值的平均值很靠近0, 这跟我们的原假设是一致的。图中的两条竖线表示两个阈值(cutoff),这里选择了x=-δ和x=δ。
在这1000个差值里面,我们发现有166个值的绝对值大于等于δ,所以这里的p值约为0.166。换句话说,在两个分组的怀孕周期没有差别的原假设下,出现这种效应的概率大约为17%。
这样的效应在一次试验中是不大可能出现的,但是这个概率是否足够小呢?我们将在下一节讨论这个问题。
习题7-1
在NSFG的数据集中,第一胎婴儿的平均体重与非第一胎婴儿的平均体重的差异为2.0盎司。请计算这个差异的p值。
提示:这里的重抽样应该用的是有放回抽样。因此应该使用random.choice,而不是random.sample(参见3.8节)。
你可以借鉴本节中我用来生成结果的代码,下载代码请访问http://thinkstats.com/hypothesis.py。