3.2 PMF的不足
如果要处理的数据比较少,PMF很合适。但随着数据的增加,每个值的概率就会降低,而随机噪声的影响就会增大。
例如,假设我们对新生儿的体重分布感兴趣。在NSFG的数据中,变量totalwgt_oz以盎司〔1〕为单位记录了新生儿的体重。图3-1分别是第一胎宝宝和其他宝宝的体重PMF。这也说明了PMF的一个不足之处:很难做比较。
〔1〕英制计量单位,1盎司=28.350克。——编者注
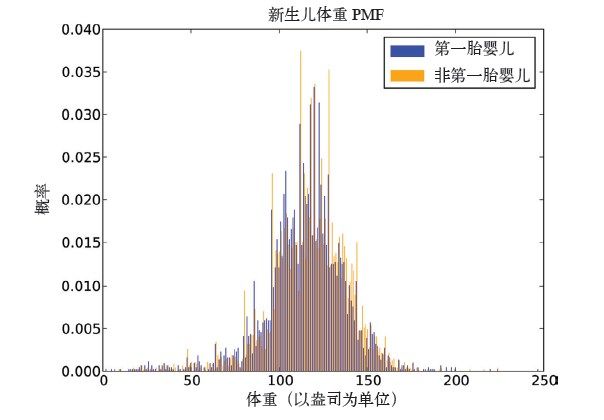
图3-1 新生儿体重PMF
整体上来看,这两个分布都是钟型曲线,均值附近的值比较多,远离均值的较大值和较小值都比较少。
但这个图中有些东西很难解读。其中有很多峰值和低谷,而且两个分布间有些很明显的差异。很难说哪些特征是显著的。此外,也不容易分辨整体的模式,比如哪个分布的均值比较大?
通过将数据分组可以解决这些问题。也就是将整个区域分成若干个不重叠的区间,然后计算每个区间内值的数量。分组很有用,但确定分组区间的大小就需要技巧了。分组区间大到能够消除噪声的时候,也会把有用的信息抹掉。
另一个解决这些问题的方法是累积分布函数(Cumulative Distribution Function,CDF)。不过在介绍CDF之前,我们先来说说百分位数(percentile)。